

This work is an nlp task comparison by simultaneously solving the verification task (If a sample belongs to the certain group ) using three unique approaches : pgm method(bayesian nets/ markov chains), simple machine learning (pos tagging, word2vec feature count etc), a deep learning method (rnn, lstm)
Supervised Classification
Classification is the task of choosing the correct class label for a given input. In basic classification tasks, each input is considered in isolation from all other inputs, and the set of labels is defined in advance. Some examples of classification tasks are:
Deciding whether an email is spam or not. Deciding what the topic of a news article is, from a fixed list of topic areas such as “sports,” “technology,” and “politics.” Deciding whether a given occurrence of the word bank is used to refer to a river bank, a financial institution, the act of tilting to the side, or the act of depositing something in a financial institution. The basic classification task has a number of interesting variants. For example, in multi-class classification, each instance may be assigned multiple labels; in open-class classification, the set of labels is not defined in advance; and in sequence classification, a list of inputs are jointly classified.
A classifier is called supervised if it is built based on training corpora containing the correct label for each input. The framework used by supervised classification is shown in 1.1.
Figure 1.1: Supervised Classification. [4]
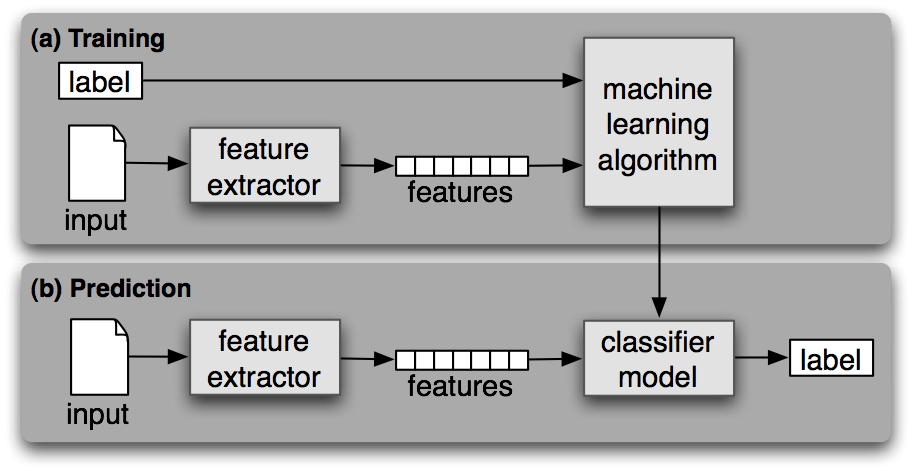
(a) During training, a feature extractor is used to convert each input value to a feature set. These feature sets, which capture the basic information about each input that should be used to classify it, are discussed in the next section. Pairs of feature sets and labels are fed into the machine learning algorithm to generate a model. (b) During prediction, the same feature extractor is used to convert unseen inputs to feature sets. These feature sets are then fed into the model, which generates predicted labels.
Deep LSTM siamese network for text similarity
It is a tensorflow based implementation of deep siamese LSTM network to capture phrase/sentence similarity using character embeddings.
This code provides architecture for learning two kinds of tasks:
-
Phrase similarity using char level embeddings [1]

-
Sentence similarity using word level embeddings [2]

For both the tasks mentioned above it uses a multilayer siamese LSTM network and euclidian distance based contrastive loss to learn input pair similairty.
Capabilities
Given adequate training pairs, this model can learn Semantic as well as structural similarity. For eg:
Phrases :
- International Business Machines = I.B.M
- Synergy Telecom = SynTel
- Beam inc = Beam Incorporate
- Sir J J Smith = Johnson Smith
- Alex, Julia = J Alex
- James B. D. Joshi = James Joshi
- James Beaty, Jr. = Beaty
For phrases, the model learns character based embeddings to identify structural/syntactic similarities.
Sentences :
- He is smart = He is a wise man.
- Someone is travelling countryside = He is travelling to a village.
- She is cooking a dessert = Pudding is being cooked.
- Microsoft to acquire Linkedin ≠ Linkedin to acquire microsoft
(More examples Ref: semEval dataset)
For Sentences, the model uses pre-trained word embeddings to identify semantic similarities.
Categories of pairs, it can learn as similar:
- Annotations
- Abbreviations
- Extra words
- Similar semantics
- Typos
- Compositions
- Summaries
Training Data
- Phrases:
- A sample set of learning person name paraphrases have been attached to this repository. To generate full person name disambiguation data follow the steps mentioned at:
https://github.com/dhwajraj/dataset-person-name-disambiguation “person_match.train” : https://drive.google.com/open?id=1HnMv7ulfh8yuq9yIrt_IComGEpDrNyo-
- A sample set of learning person name paraphrases have been attached to this repository. To generate full person name disambiguation data follow the steps mentioned at:
- Sentences:
- A sample set of learning sentence semantic similarity can be downloaded from:
“train_snli.txt” : https://drive.google.com/open?id=1itu7IreU_SyUSdmTWydniGxW-JEGTjrv
This data is is in the format of the SNLI project :
https://nlp.stanford.edu/projects/snli/
Original dataset: Was of the form of separate csv files that were combined to one csv using the sql query provided https://www.kaggle.com/sirpunch/meetups-data-from-meetupcom/data
- A sample set of learning sentence semantic similarity can be downloaded from:
“train_snli.txt” : https://drive.google.com/open?id=1itu7IreU_SyUSdmTWydniGxW-JEGTjrv
This data is is in the format of the SNLI project :
Environment
- numpy 1.11.0
- tensorflow 1.2.1
- gensim 1.0.1
- nltk 3.2.2
How to run
Training
Evaluation
Performance
Phrases:
- Training time: = 1 complete epoch : ? (training requires atleast 30 epochs)
- Contrastive Loss : ?
- Evaluation performance : similarity measure for 100,000 pairs (8core cpu) = ?
- Accuracy ?
Sentences:
- Training time: (8 core cpu) = 1 complete epoch : ? (training requires atleast 50 epochs)
- Contrastive Loss : ?
- Evaluation performance : similarity measure for 100,000 pairs (8core cpu) = ?
- Accuracy ?