

This work tries to reproduce the results of SeqGAN: Sequence Generative Adversarial Nets with Policy Gradient (aka SeqGan). It uses a RNN sequence as a generator and the discriminator Modeling the data generator as a stochastic policy in reinforcement learning (RL),SeqGAN bypasses the generator differentiation problem by directly performing gradient policy update.
SeqGAN
Requirements:
- Tensorflow r1.0.1
- Python 2.7
- CUDA 7.5+ (For GPU)
Introduction
Apply Generative Adversarial Nets to generating sequences of discrete tokens.
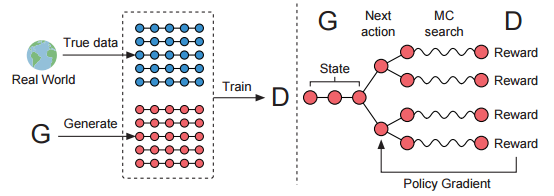
The illustration of SeqGAN. Left: D is trained over the real data and the generated data by G. Right: G is trained by policy gradient where the final reward signal is provided by D and is passed back to the intermediate action value via Monte Carlo search.
The research paper SeqGAN: Sequence Generative Adversarial Nets with Policy Gradient has been accepted at the Thirty-First AAAI Conference on Artificial Intelligence (AAAI-17).
We provide example codes to repeat the synthetic data experiments with oracle evaluation mechanisms. To run the experiment with default parameters:
$ python sequence_gan.py
You can change the all the parameters in sequence_gan.py.
The experiment has two stages. In the first stage, use the positive data provided by the oracle model and Maximum Likelihood Estimation to perform supervise learning. In the second stage, use adversarial training to improve the generator.
After running the experiments, you could get the negative log-likelihodd performance saved in save/experiment-log.txt like:
pre-training...
epoch: 0 nll: 10.1716
epoch: 5 nll: 9.42939
epoch: 10 nll: 9.2388
epoch: 15 nll: 9.11899
epoch: 20 nll: 9.13099
epoch: 25 nll: 9.14474
epoch: 30 nll: 9.12539
epoch: 35 nll: 9.13982
epoch: 40 nll: 9.135
epoch: 45 nll: 9.13081
epoch: 50 nll: 9.10678
epoch: 55 nll: 9.10694
epoch: 60 nll: 9.10349
epoch: 65 nll: 9.10403
epoch: 70 nll: 9.07613
epoch: 75 nll: 9.091
epoch: 80 nll: 9.08909
epoch: 85 nll: 9.0807
epoch: 90 nll: 9.08434
epoch: 95 nll: 9.08936
epoch: 100 nll: 9.07443
epoch: 105 nll: 9.08305
epoch: 110 nll: 9.06973
epoch: 115 nll: 9.07058
adversarial training...
epoch: 0 nll: 9.08457
epoch: 5 nll: 9.04511
epoch: 10 nll: 9.03079
epoch: 15 nll: 8.99239
epoch: 20 nll: 8.96401
epoch: 25 nll: 8.93864
epoch: 30 nll: 8.91642
epoch: 35 nll: 8.87761
epoch: 40 nll: 8.88582
epoch: 45 nll: 8.8592
epoch: 50 nll: 8.83388
epoch: 55 nll: 8.81342
epoch: 60 nll: 8.80247
epoch: 65 nll: 8.77778
epoch: 70 nll: 8.7567
epoch: 75 nll: 8.73002
epoch: 80 nll: 8.72488
epoch: 85 nll: 8.72233
epoch: 90 nll: 8.71473
epoch: 95 nll: 8.71163
epoch: 100 nll: 8.70113
epoch: 105 nll: 8.69879
epoch: 110 nll: 8.69208
epoch: 115 nll: 8.69291
epoch: 120 nll: 8.68371
epoch: 125 nll: 8.689
epoch: 130 nll: 8.68989
epoch: 135 nll: 8.68269
epoch: 140 nll: 8.68647
epoch: 145 nll: 8.68066
epoch: 150 nll: 8.6832
Note: this code is based on the previous work by ofirnachum. Many thanks to ofirnachum.